N.B. All analyses in the following post were performed by William Palmer, a Senior Data Scientist at Gencove
Introduction
The 1000 Genomes Phase 3 (1KGP3) has been a vital open-access resource for genomics research since its initial release and accompany publication in 2015 [1]. However, there have since been releases of similar open-access genomic datasets based on high-coverage sequence datasets, including a New York Genome Center-resequenced version of the expanded version of the same cohort including 602 trios resequenced at an average depth of 30x [2], as well as projects such as the Human Genome Diversity Project (HGDP) which recently published high depth sequence on 929 individuals from a diverse set of human populations [3].
Recently, the Martin Lab produced a harmonized dataset of 4096 high quality genomes comprising the whole genome sequences from [2] and [3] and publicly released individual level data for the sample set, including phased VCFs containing SNPs, indels, and SVs.
At Gencove, our current default reference panel for humans on build 38 of the human genome reference assembly uses a version of the expanded panel (hereafter denoted NYGC1KG) released along with [2] (specifically, it is based on the files available here) for imputation from low-pass sequence data. Since one of our priorities at Gencove is to stay current in terms of haplotype reference panels available for standard analyses, we investigated whether the harmonized callset comprising the 1KGP3 and the HGDP (hereafter referred to HGDP1KG) afforded increased imputation accuracy from low-pass sequence compared to the NYGC1KG panel.
In order to do so, we selected 26 individuals present in both [2] and the HGDP1KG. These individuals included NA12878 as well as representatives of all population and super population groups. High coverage sequences for these individuals were downsampled to 1x, a target depth commonly used for low-pass sequencing. Following that, we imputed the downsampled individuals using the NYGC1KGP3 as well as the HGDP1KG reference panels in a leave-one-out (LOO) manner and evaluated the imputed genotypes for those individuals against the “left-out” genotypes from the respective panels. For all imputation analyses we used GLIMPSE [5].
We also performed some basic comparisons between the two panels.
Panel comparison
We performed a couple basic analyses comparing the two reference panels — for simplicity, we restricted ourselves to chromosome 1. Briefly, the HGDP1KG contains roughly twice as many SNPs as the NYGC1KG, the majority of which are rare, and contains roughly 60% as many indels.
We also performed a basic estimation of switch error rate (SER) in the phased genotypes for NA12878 in each panel, where the publicly available Platinum Genomes VCF for NA12878 was treated as the ground truth. We observed that the SER for NA12878 in HGDP1KG was ~60% higher than for the same individual in the NYGC1KG (0.38% vs 0.24%), possibly due to the fact that [2] utilized pedigree-informed statistical phasing, whereas [4] did not.
Results
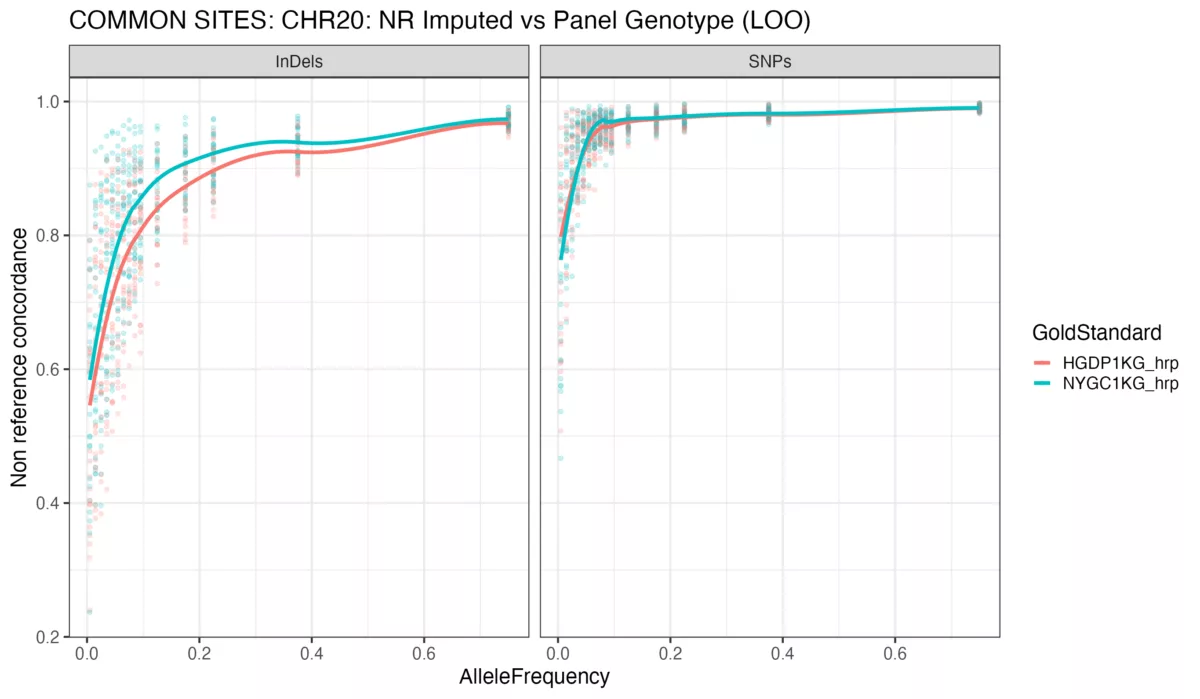
To evaluate imputation results, we evaluated the non-reference concordance of the imputed genotypes to the gold standards (i.e. the left-out genotypes in the reference panels). Since the two panels have a significant but not complete overlap in variants (as the HGDP1KG contains a superset of the NYGC1KG), we evaluated performance at both (1) all sites in the panel to which a sample was imputed (restricted to chromosome 1), and (2) all overlapping sites between the two panels (restricted to chromosome 20). We stratified results by superpopulation and alternate allele frequency (with respect to the respective panels).
All sites
This section contains results evaluated at all sites in chromosome 1 in a given reference panel.
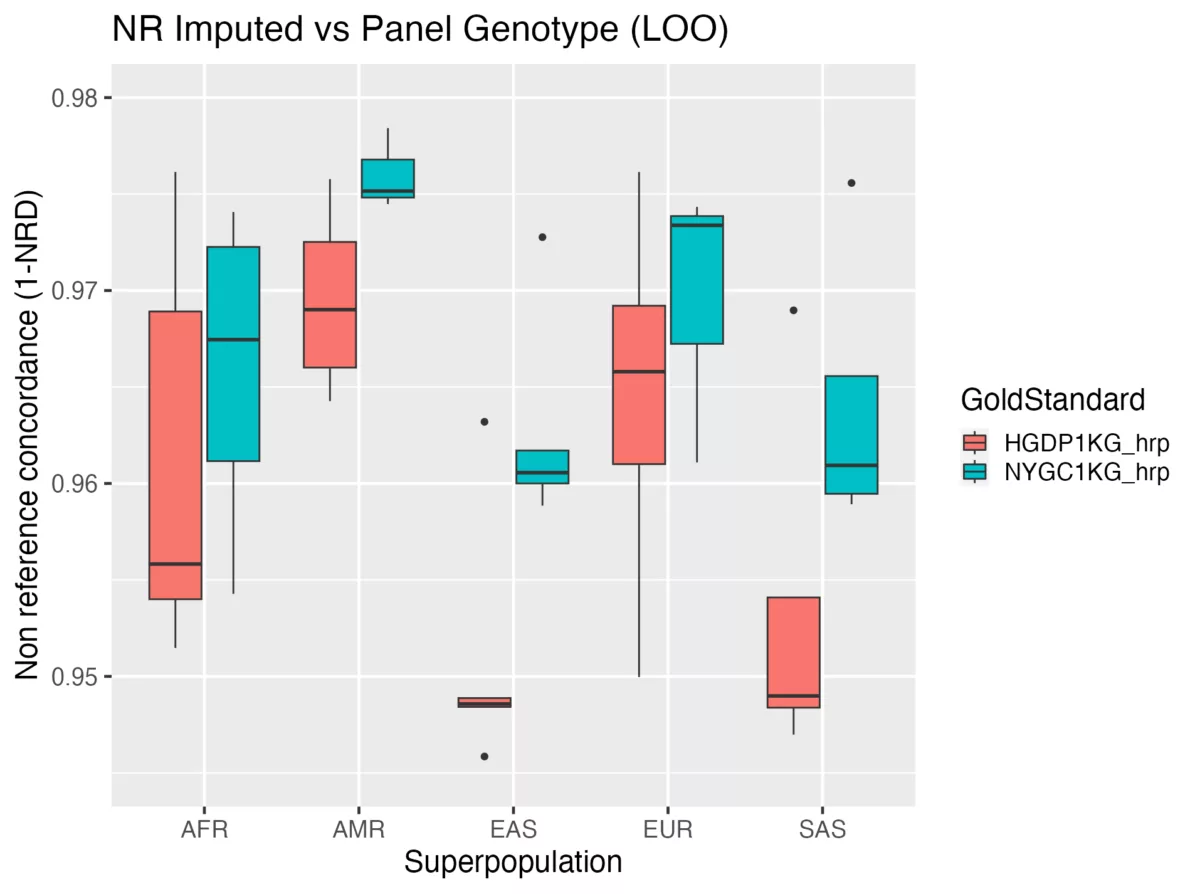
Figure 1 shows the non-reference concordance for the imputed vs panel (gold-standard) genotypes at all sites, stratified by superpopulation. We see that across all superpopulations, the NYGC1KG on average performs better.
Table 1 shows a quantitative breakdown of the mean and standard deviation of NRC for the cohort stratified by variant type (SNP or indel). Notably, while both SNP and indel imputation performed better when using the NYGC1KG panel, indels imputed considerably worse using the HGDP1KG compared to SNPs.
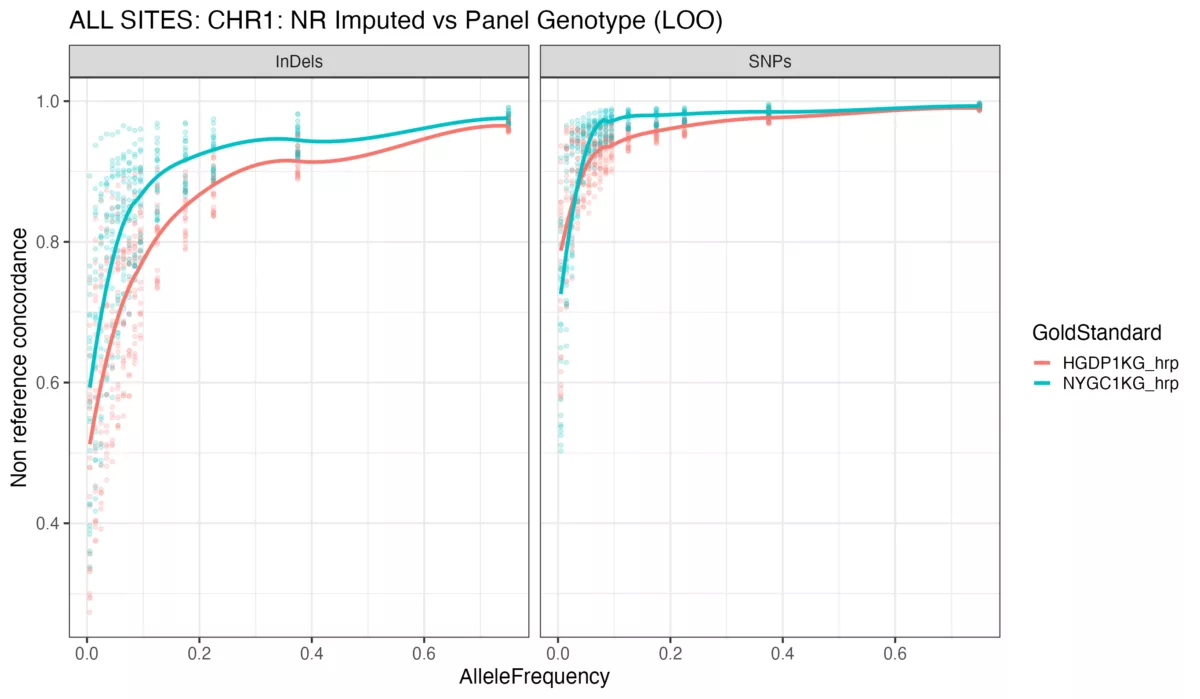
We also stratified non-reference concordance results by alternate allele frequency with respect to the gold-standard reference panel and examined the differences between the use of the two panels. Figure 2 shows these results, with each pane depicting results from the two variant types (SNPs vs indels). Across the indel allele frequency spectrum, the NYGC1KG performed better on average, as well as for common SNPs. However, at the rare allele frequency regime of the SNP set, the HGDP1KG displayed superior performance, likely due to the presence of more haplotypes tagging rare alleles in the HGDP1KG due to its increased sample size.